


0x00:前言
信息收集相对于渗透测试前期来说是非常重要的,因为只有我们掌握了目标网站足够多的信息之后,才能方便我们更好地对其进行渗透测试.
正所谓: 知己知彼 百战不殆
渗透网站的信息收集到底要收集哪些信息呢?
接下来,我就给大家整理了一下我自己在渗透测试中常见的一些需要收集的信息.
- 网站的真实IP
- 端口\端口服务信息
- 网站的“指纹”信息
- 子域名
- 备案信息
- 域名历史解析
- SSL证书查询
- 域名关联邮箱信息
- waf探测(可以参考之前的文章:sqlmap +外部代理池绕过IP拦截)
- 目录的探测(可以参考之前的文章:扫目录+N多代理IP绕过拦截)
- DNS枚举
- 等等
但是,每次需要自己去一个一个查,然后再去收集结果,很费时间.这个时候就需要自己去整合所有的资源,统一查询完输出想要的结果.
效果图:


0x01:过程
一.调用现有已知的网站如下:
https://site.ip138.com
http://whatweb.bugscaner.com
https://domains.yougetsignal.com二.说明:
1.扫描端口采用python的nmap模块,使用前需要:
pip3 install python-nmap2.采用异步Scanner模式:
nm = nmap.PortScanner()
或者
nm = nmap.PortScannerAsync()实现异步扫描,可以进行多线程扫描
3.nmap扫描时这里采用”-Pn”模式。”-Pn”命令是告诉Nmap扫描时不用ping远程主机,从而来避开一些防火墙的拦截。
三.代码整合:
# -*- encoding: utf-8 -*-
#/usr/bin/python3
#Share:Apibug.com
#Prompt before use:----pip install nmap
#端口\端口服务\指纹\子域名\备案查询\IP历史解析
import nmap,sys,re,json,requests
def callback_result(host, scan_result):
Port_range=re.findall("services\".*\"}}, \"scanstats\"",json.dumps(scan_result))#.replace("}}, \"scanstats\"\'","")
#print (len(a))
for x in Port_range:
print ("Scan port range:"+x.strip("}}, \"scanstats\"").strip("ervices\": \""))
Port_statere=re.findall("user-set\"},.*",json.dumps(scan_result))
#print (Port_statere)
#筛选出开放的端口
for State_filtering in Port_statere:
port=re.findall(".{9}.state.{8}",State_filtering)
Open_port=re.findall("\d+",str(port).replace("\": {\"state\": \"open\'","").replace("[\' {\"",""))
print ("开放的端口:","\n",Open_port)
print ("------------------------------------------------------------------------------------------")
#筛选出端口开放的服务
for Open_service in Port_statere:
server=re.findall("name.{10}",Open_service)
x=str(server).replace("\'name\": \"","")
print ("开放的端口服务:","\n",x)
print ("------------------------------------------------------------------------------------------")
#print ("Test weak password ing...")
#url="http://whatweb.bugscaner.com/what.go"
try:
#域名解析历史
history='https://site.ip138.com/'+sys.argv[1]
Domain_history=requests.get (history,headers={ 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' }).text
print("域名历史解析结果:")
print (str(re.findall("\d\d\d\d-\d\d-\d\d-----\d\d\d\d-\d\d-\d\d|target=\"_blank\">.*",str(str(re.findall("<span class=\"date\">.*\n.*",Domain_history)).replace("\'<span class=\"date\">","").replace(", ","\n").replace("[","").replace("]","")))).replace("target=\"_blank\">","").replace("</a>\'","").replace(", ","\n").replace("\'","").replace("</a>\\",""))
print ("------------------------------------------------------------------------------------------")
#指纹识别
headers={
'Host': 'whatweb.bugscaner.com',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest'
}
data={'url':sys.argv[1],'location_capcha':'no'}
cms=requests.post("http://whatweb.bugscaner.com/what.go",headers=headers,data=data).text
newline=str(cms).replace(", ","\n").replace("{","").replace("}","").replace("\"status\": 99","-------------------------------------")#去除杂项
print("指纹识别结果:")
print (newline.encode('utf-8').decode('unicode_escape'))
print ("------------------------------------------------------------------------------------------")
#旁站搜索
Remove_prefix=re.findall("[a-zA-Z-]+.com|[a-zA-Z-]+.org|[a-zA-Z-]+.cn",sys.argv[1])
url="https://domains.yougetsignal.com/domains.php"
next_site=requests.post(url,headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko"},data={"remoteAddress":str(Remove_prefix).replace("[\'","").replace("\']","")}).text
print ("旁站搜索结果:")
print (str(re.findall("domainArray.*",next_site)).replace("\", \"\"], [\"","\n").replace("\", \"\"]]}\']","").replace("[\'domainArray\":[[\"",""))
print ("------------------------------------------------------------------------------------------")
#子域名搜索
#x='https://site.ip138.com/'+Remove_prefix+'/domain.htm'
subdomain=requests.get ('https://site.ip138.com/'+str(Remove_prefix).replace("[\'","").replace("\']","")+'/domain.htm',headers={ 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' }).text
print ("子域名搜索结果:")
print ((str(re.findall("target=\"_blank\">.[^\s]*",str(re.findall("target=\"_blank\">.*",str(re.findall("<a href=.*</a></p>",subdomain)))))).replace("target=\"_blank\">","").replace("</a></p>","").replace("\\\\\\\',\', ","\n").replace("\']","").replace("[","").replace("\\\\\\\\","")))
print ("------------------------------------------------------------------------------------------")
#备案号查询
beian=requests.get ('https://site.ip138.com/'+str(Remove_prefix).replace("[\'","").replace("\']","")+'/beian.htm',headers={ 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' }).text
print("备案号查询结果:")
print (str(re.findall("target=\"_blank\">.*",str(re.findall("IC.*</a>",beian)))).replace("[\'target=\"_blank\">","").replace("</a>\\']\']",""))
print ("------------------------------------------------------------------------------------------")
except Exception as e:
print (e)
# 异步Scanner
nm = nmap.PortScannerAsync()
try:
nm.scan(sys.argv[1], ports=sys.argv[2], arguments='-Pn',callback=callback_result)
if "gov" and "edu" in sys.argv[1]:
print ("FBI warning:please don't scan gov/edu maliciously!!!")
else:
# 以下是必须写的,否则你会看到一运行就退出,没有任何的结果
while nm.still_scanning(): nm.wait(2)
except:
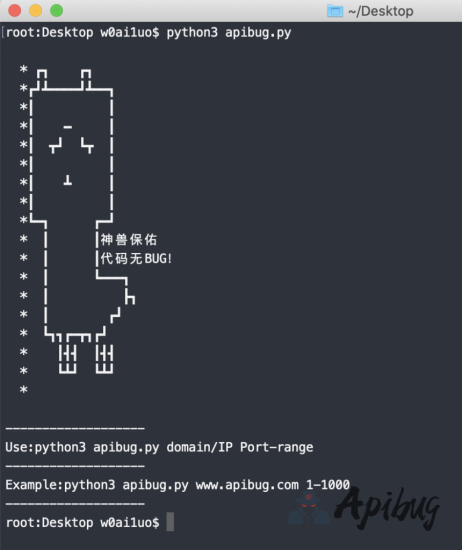
info='''
* ┏┓ ┏┓
*┏┛┻━━━━┛┻━━┓
*┃ ┃
*┃ ━ ┃
*┃ ┳┛ ┗┳ ┃
*┃ ┃
*┃ ┻ ┃
*┃ ┃
*┗━┓ ┏━┛
* ┃ ┃神兽保佑
* ┃ ┃代码无BUG!
* ┃ ┗━━━┓
* ┃ ┣┓
* ┃ ┏┛
* ┗┓┓┏━┳┓┏┛
* ┃┫┫ ┃┫┫
* ┗┻┛ ┗┻┛
*
'''
print (info)
print ("-------------------")
print ("Use:python3 apibug.py domain/IP Port-range")
print ("-------------------")
print ("Example:python3 apibug.py www.apibug.com 1-1000")
print ("-------------------")
四.功能说明:
这里只是对”端口\端口服务\指纹\子域名\备案查询\IP历史解析”的信息收集,
后续如果需要增加其它的信息查询结果,可随意扩展增加。
本站代码教程仅供学习交流使用请勿商业运营,严禁二次倒卖,否则ban账号处理!
© 版权声明
THE END
 会员专属
会员专属












