


0x00:简介
在渗透测试的时候,很担心平时在扫WEB目录的时候,频繁的请求会容易被封IP.被封IP以后.要么等上一段时间,要么更换自己的IP.重新启动扫描器.这样的效率很低下,也很浪费自己的工作时间.
此时,代理IP池进入了我的考虑范围.让代理+扫目录的脚本.自动化的去更新IP.不用再去担心IP是否被封.
但是网上流传了N多的WEB目录扫描器.用别人的东西,心里都有那么点不自然,一个是担心有后门,一种是自己也想向大佬们学习.拥有自己的目录扫描器.
本文的python脚本为纯自学后编写,如有不规范请大佬指点(望轻喷,感谢 !!!)
0x01:编写
1、代理IP采集地址
http://www.66ip.cn/
主要是免费,但是N多已经不能连接了
得自己去做验证,害!!
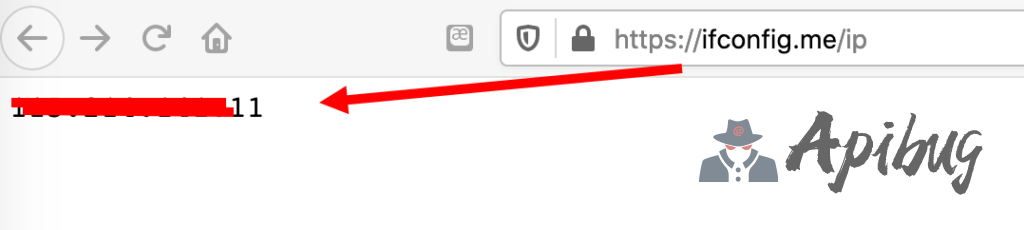
2、IP验证地址
https://ifconfig.me

它会显示你当前的所在IP
3、思路
首先爬取代理IP,并用正则规则给匹配出来所有IP
url="http://www.66ip.cn/nmtq.php?getnum=100"#爬取100个做例子headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'}r=requests.get(url,headers=headers).textip_proxy=re.findall("((?:[0-9]{1,3}\.){3}[0-9]{1,3}:*[0-9]*)", r)#正则匹配IPfor i in ip_proxy:#用for循环取出IP并赋予iprint (i)url="http://www.66ip.cn/nmtq.php?getnum=100"#爬取100个做例子 headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'} r=requests.get(url,headers=headers).text ip_proxy=re.findall("((?:[0-9]{1,3}\.){3}[0-9]{1,3}:*[0-9]*)", r)#正则匹配IP for i in ip_proxy:#用for循环取出IP并赋予i print (i)url="http://www.66ip.cn/nmtq.php?getnum=100"#爬取100个做例子 headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'} r=requests.get(url,headers=headers).text ip_proxy=re.findall("((?:[0-9]{1,3}\.){3}[0-9]{1,3}:*[0-9]*)", r)#正则匹配IP for i in ip_proxy:#用for循环取出IP并赋予i print (i)
我们来继续看Python中proxies的编写规则
proxy={'协议':'ip:端口'}proxy={'协议':'ip:端口'}proxy={'协议':'ip:端口'}
继续
types=”https“proxys={}proxys[types.lower()]='%s'%i #把上面的i值拼接进去print (proxys)#输出例子:{'https': '1.2.3.4:3308'}types=”https“ proxys={} proxys[types.lower()]='%s'%i #把上面的i值拼接进去 print (proxys)#输出例子:{'https': '1.2.3.4:3308'}types=”https“ proxys={} proxys[types.lower()]='%s'%i #把上面的i值拼接进去 print (proxys)#输出例子:{'https': '1.2.3.4:3308'}
继续来看扫描WEB的部分
r= requests.get (url,headers=headers,proxies=proxys,timeout=8).status_code #发送请求并确定状态码=200if r==200:sys.stdout.write('[200] %s\n' %url)elif r==301:sys.stdout.write('[--301--] %s\n' %url)#这里只是判断200的状态码跟301的状态码,后续可加!r= requests.get (url,headers=headers,proxies=proxys,timeout=8).status_code #发送请求并确定状态码=200 if r==200: sys.stdout.write('[200] %s\n' %url) elif r==301: sys.stdout.write('[--301--] %s\n' %url) #这里只是判断200的状态码跟301的状态码,后续可加!r= requests.get (url,headers=headers,proxies=proxys,timeout=8).status_code #发送请求并确定状态码=200 if r==200: sys.stdout.write('[200] %s\n' %url) elif r==301: sys.stdout.write('[--301--] %s\n' %url) #这里只是判断200的状态码跟301的状态码,后续可加!
思路差不多讲到这,来看成品
#/usr/bin/python3import requests,sys,threadingfrom queue import Queue#多线程实现扫描目录class DirScan(threading.Thread):def __init__(self,queue):threading.Thread.__init__(self)self.queue=queuedef run(self):#获取队列中的URLwhile not self.queue.empty():url=self.queue.get()with open('ok.txt','r') as file: list = [www.strip() for www in file.readlines()]headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'}try:for www in list:tar=requests.get(url,headers=headers,proxies=eval(www),timeout=10,verify=False)if tar.status_code==200:#这里只显示200的状态码,需要可加其他状态码做筛选urls={url}print (list(urls))except Exception as e:passdef start(url,count):queue=Queue()f=open ('dir.txt','r')for i in f:queue.put(url+i.rstrip('\n'))#多线程threads=[]thread_count=int(count)for i in range(thread_count):threads.append(DirScan(queue))for t in threads:t.start()for t in threads:t.join()if __name__=="__main__":url=sys.argv[1]count=10start(url,count)#/usr/bin/python3 import requests,sys,threading from queue import Queue #多线程实现扫描目录 class DirScan(threading.Thread): def __init__(self,queue): threading.Thread.__init__(self) self.queue=queue def run(self): #获取队列中的URL while not self.queue.empty(): url=self.queue.get() with open('ok.txt','r') as file: list = [www.strip() for www in file.readlines()] headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'} try: for www in list: tar=requests.get(url,headers=headers,proxies=eval(www),timeout=10,verify=False) if tar.status_code==200:#这里只显示200的状态码,需要可加其他状态码做筛选 urls={url} print (list(urls)) except Exception as e: pass def start(url,count): queue=Queue() f=open ('dir.txt','r') for i in f: queue.put(url+i.rstrip('\n')) #多线程 threads=[] thread_count=int(count) for i in range(thread_count): threads.append(DirScan(queue)) for t in threads: t.start() for t in threads: t.join() if __name__=="__main__": url=sys.argv[1] count=10 start(url,count)#/usr/bin/python3 import requests,sys,threading from queue import Queue #多线程实现扫描目录 class DirScan(threading.Thread): def __init__(self,queue): threading.Thread.__init__(self) self.queue=queue def run(self): #获取队列中的URL while not self.queue.empty(): url=self.queue.get() with open('ok.txt','r') as file: list = [www.strip() for www in file.readlines()] headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/12.0 Safari/1200.1.25'} try: for www in list: tar=requests.get(url,headers=headers,proxies=eval(www),timeout=10,verify=False) if tar.status_code==200:#这里只显示200的状态码,需要可加其他状态码做筛选 urls={url} print (list(urls)) except Exception as e: pass def start(url,count): queue=Queue() f=open ('dir.txt','r') for i in f: queue.put(url+i.rstrip('\n')) #多线程 threads=[] thread_count=int(count) for i in range(thread_count): threads.append(DirScan(queue)) for t in threads: t.start() for t in threads: t.join() if __name__=="__main__": url=sys.argv[1] count=10 start(url,count)
采用多线程去运行,不然单线程会很慢
注释:
需要在脚本的目录下存放WEB目录的文件,注意一点的是,路径不能有中文。
“dir.txt” 存放路径文件,例子如下

“ok.txt” 存放能用的代理IP,例子如下

运行例子

这里有个小弊端
就是用多少代理,就会出现匹配多少结果
如果你觉得不好看,可以自己加一个去重的参数
0x02:后话
一、声明:请勿做非法攻击任何网站的行为与任何未授权的行为.
后果请自行承担责任!!!
二、代码与思路有很多不足之处,请各位大佬不吝赐教,还请您优化优化.
鄙人将不断的改进,不断的的优化
本站代码教程仅供学习交流使用请勿商业运营,严禁二次倒卖,否则ban账号处理!
© 版权声明
扫目录+N多代理IP绕过拦截-Apibug
本文链接:https://www.apibug.com/iosre/716.html
THE END
 会员专属
会员专属













请登录后查看评论内容